Rtwitter Package Tutorial
RTwitter is a package to analyze and visualize some Twitter analytics, mostly descriptive ones. All visualizations just need one line of code, that’s it. In this tutorial, we will try to go through most of the functions in the package.
Getting started
First, let’s get started by installing the package and getting the example dataset, e.g. tweets on Ukraine.
# install.packages("devtools")
devtools::install_github("selimyaman/Rtwitter")
library(Rtwitter)If R asks if you want to update the dependency packages, you can go ahead and say none.
Then, let’s get the example data:
tweets <- Rtwitter::tw
dim(tweets)## [1] 500 31This dataset has got 500 tweets and 31 variables (columns).
Now, let’s start exploring some of the functions from the package.
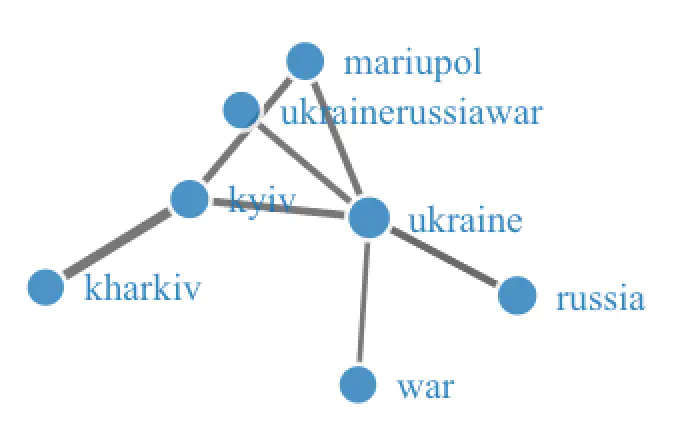
First, my favorite, word network. This creates a network of most used words - how they associate with each other:
word.network(tweets)The word ukraine has close associations with russia, war, kyiv etc. Not that surprising maybe, but it’s a cool graph!
Now, my second favurite: Do a sentiment analaysis with a click.
This is not RoBERTa or VADER, but it’s still useful for an initial inspection of sentiments. Depending on how big your dataset is, this might take a while. For the example data, it took less than 30 seconds.
extract_sentiments(tweets)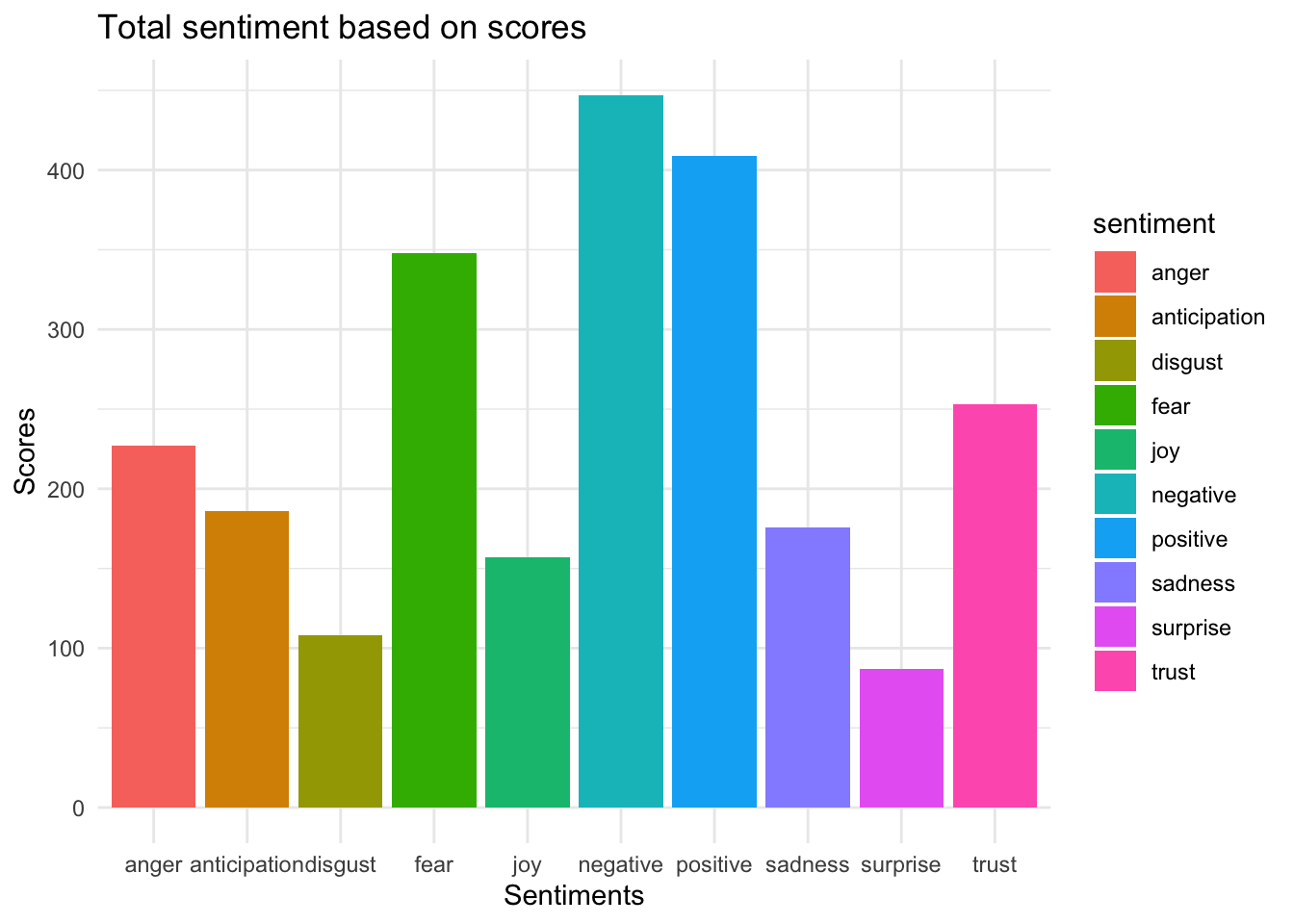
We see the negative sentiment is the dominant one here - as we would expect because the tweets are… well, on war.
Let’s see who tweeted most on this matter:
most.active(tweets) These are the accounts that tweeted most on the Ukraine issue, from our small sample.
These are the accounts that tweeted most on the Ukraine issue, from our small sample.
What were the most used emojis, any guesses?
Considering the most dominant sentiment was negative, I would expect to see some not-so-good emojis as well. Or maybe some flags? Let’s see:
most.emo(tweets)## # A tibble: 10 × 2
## emoji n
## <chr> <int>
## 1 🇺🇦 38
## 2 ⚠️ 25
## 3 ⚡ 25
## 4 ⬅️ 18
## 5 🔻 14
## 6 👇 13
## 7 💔 12
## 8 🔴 10
## 9 🤬 9
## 10 ⛔ 8Next: What are the most frequently used words?
most.freq.words(tweets)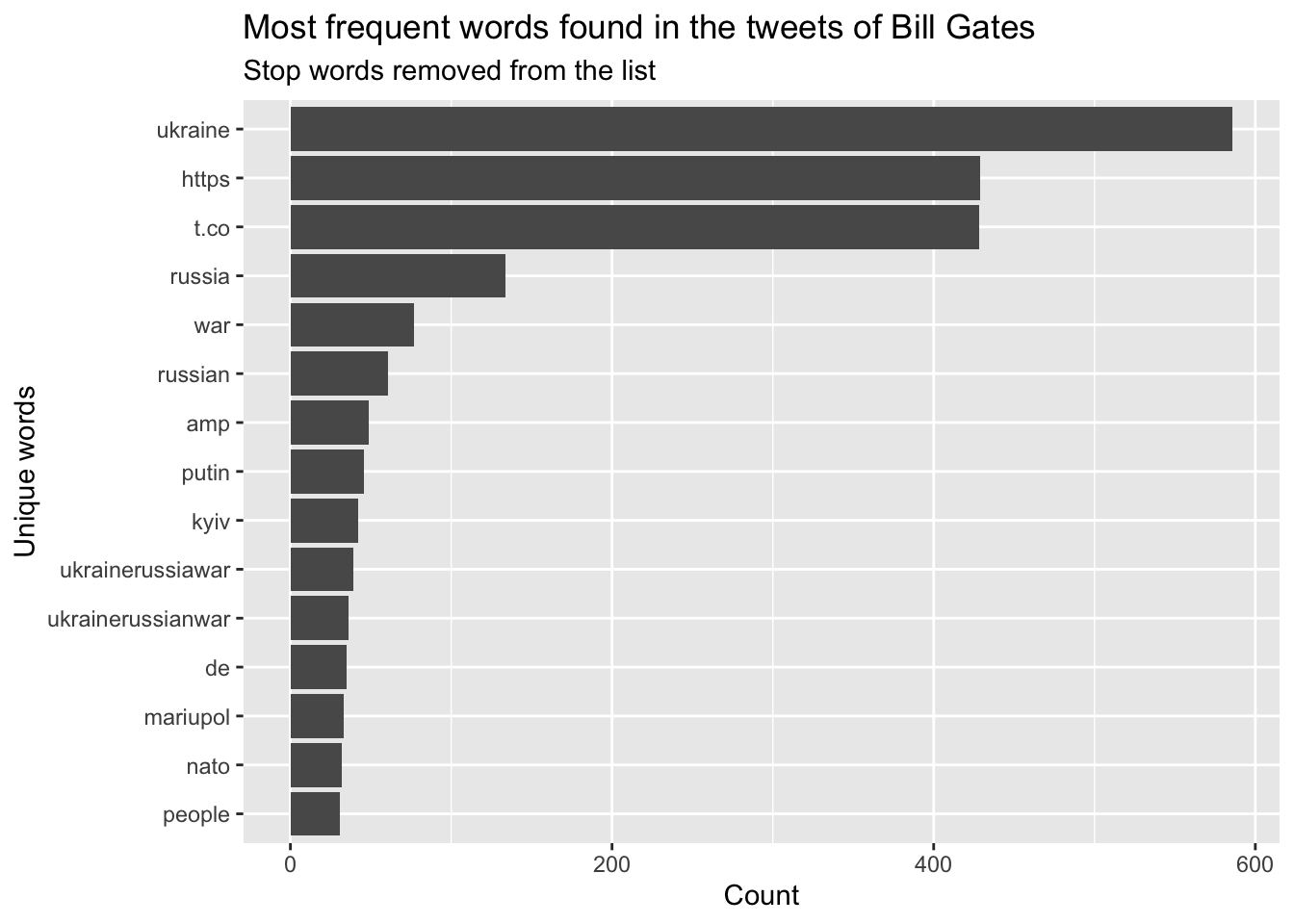
Of course it’s Ukraine - because we gathered the tweets using the keyword ‘ukraine’.
Next: What are the most retweeted and liked tweets? Let’s see them:
most.retweets(tweets)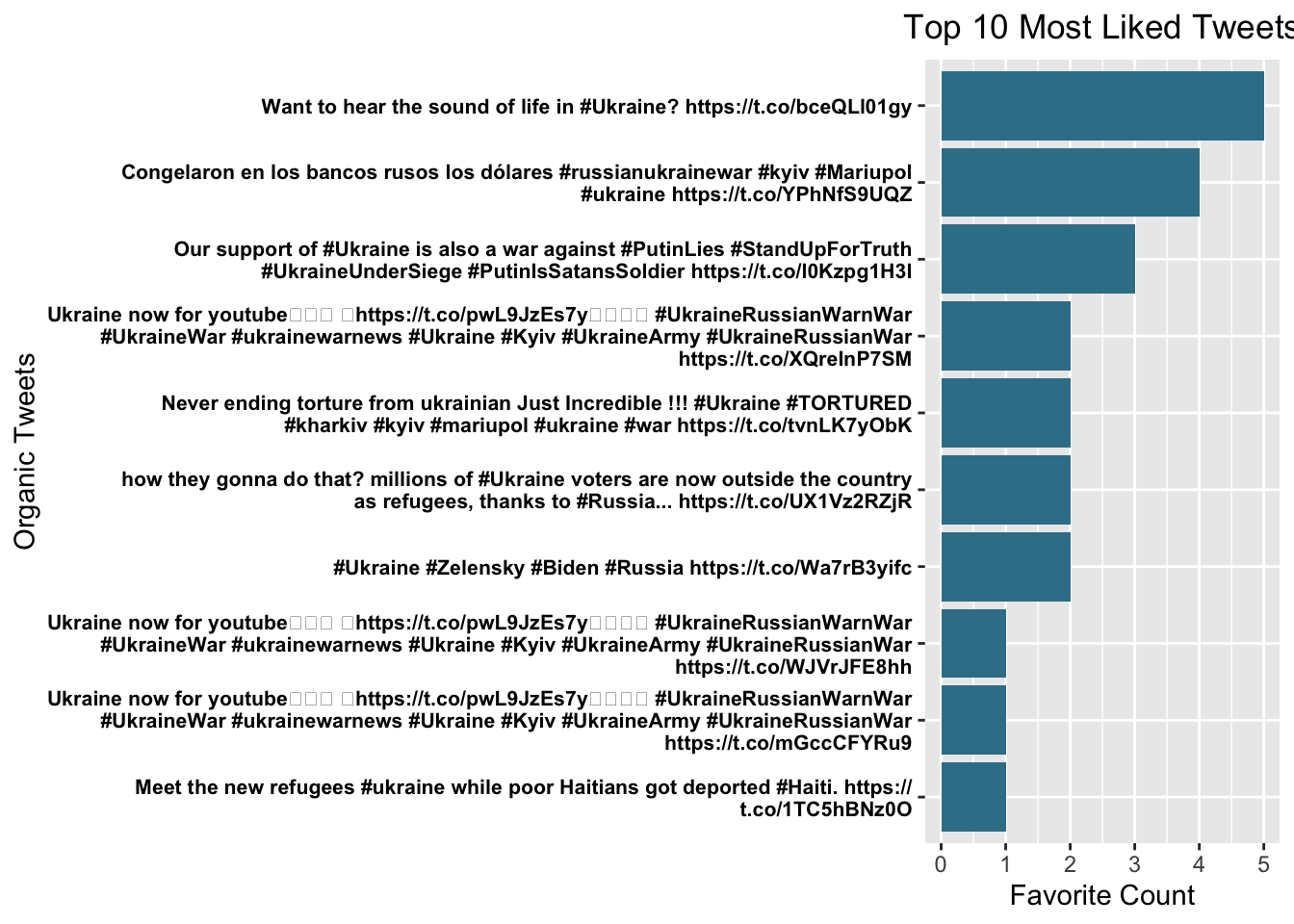
most.liked(tweets)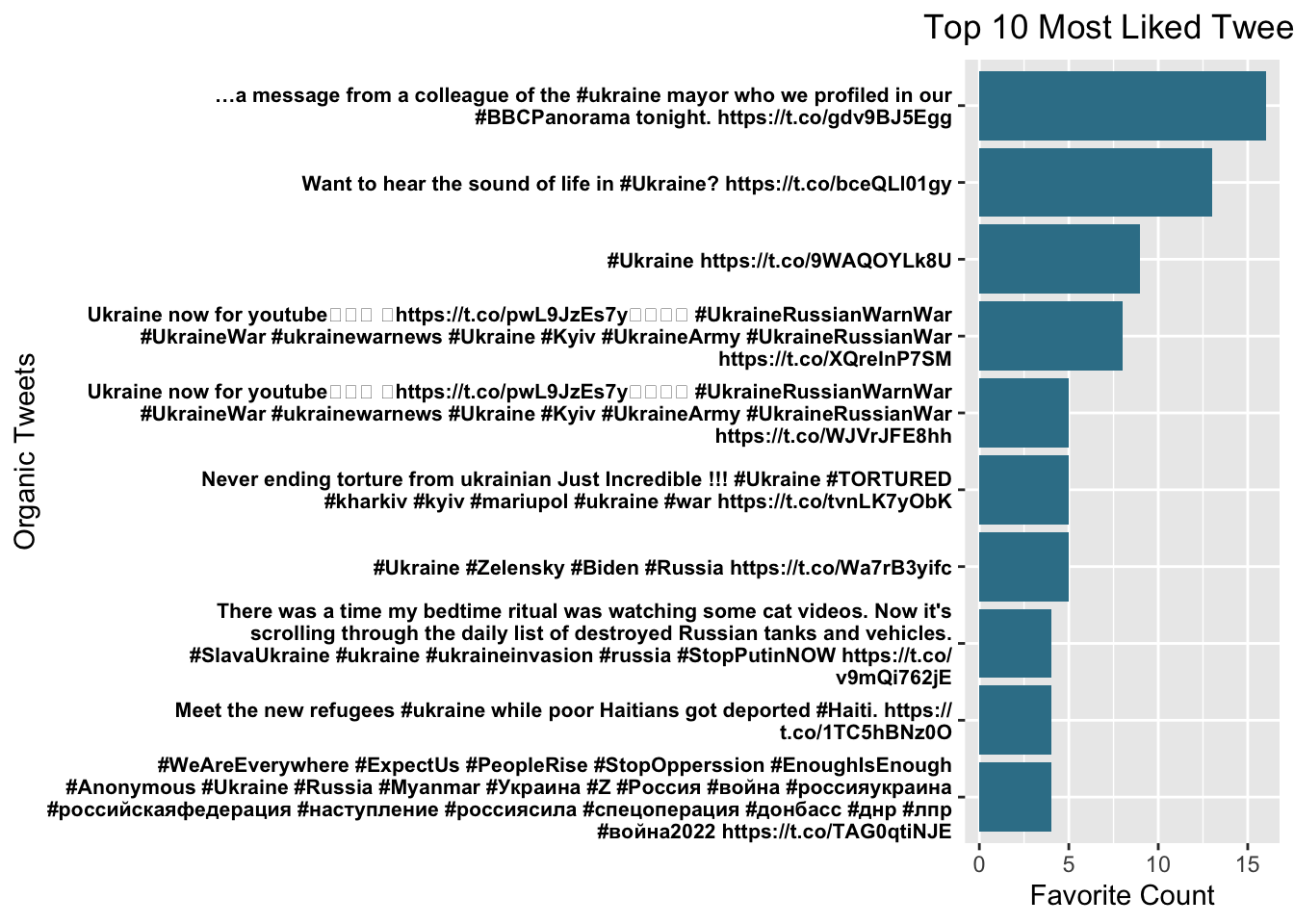
All right, let’s see user locations. Where were our users from?
user.locations(tweets)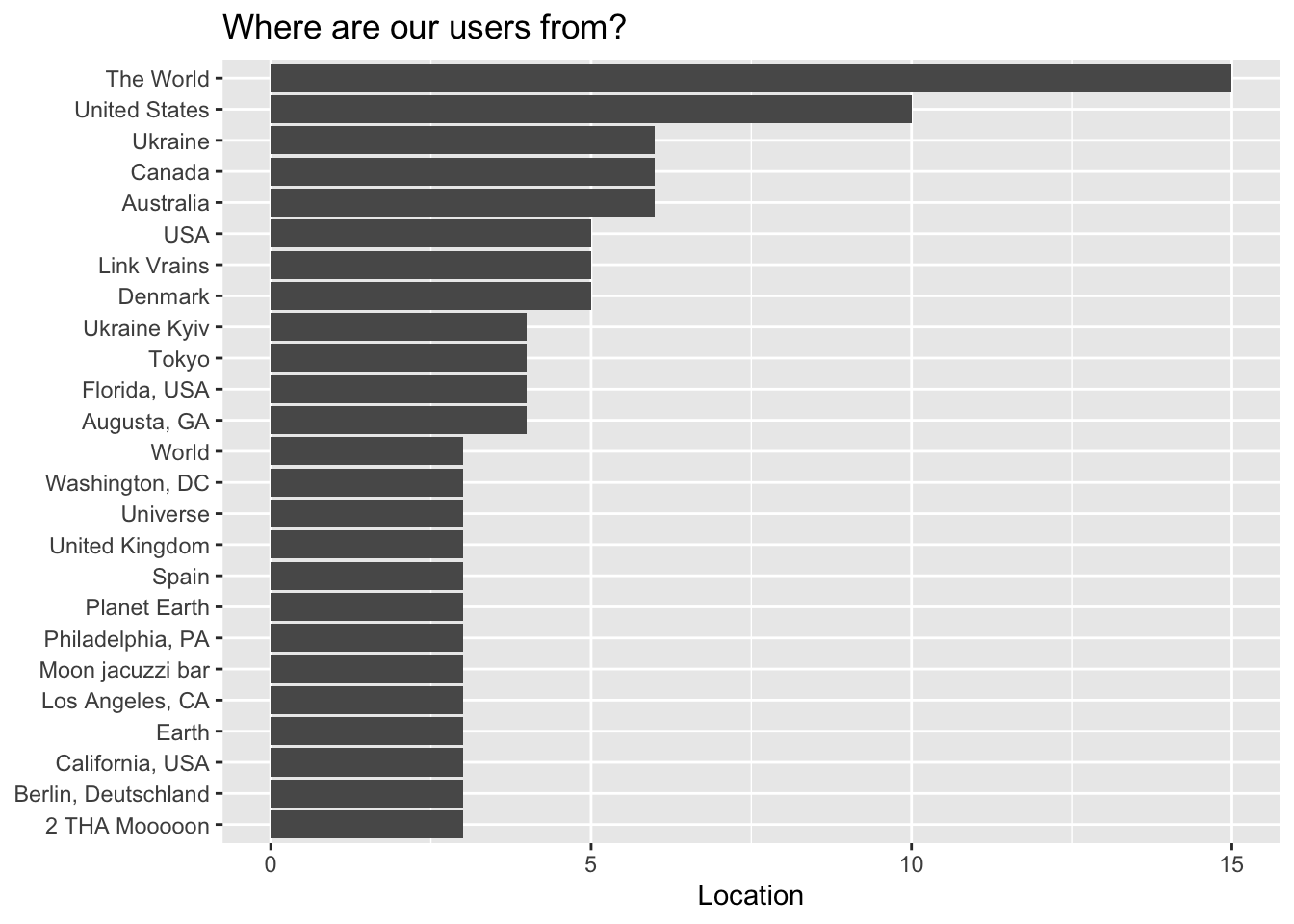 This is based on what users write on their bios, so we can see things like ‘hell’ or ‘Moon’. But most people give us more formal location names, thankfully.
This is based on what users write on their bios, so we can see things like ‘hell’ or ‘Moon’. But most people give us more formal location names, thankfully.
top.hashtags(tweets)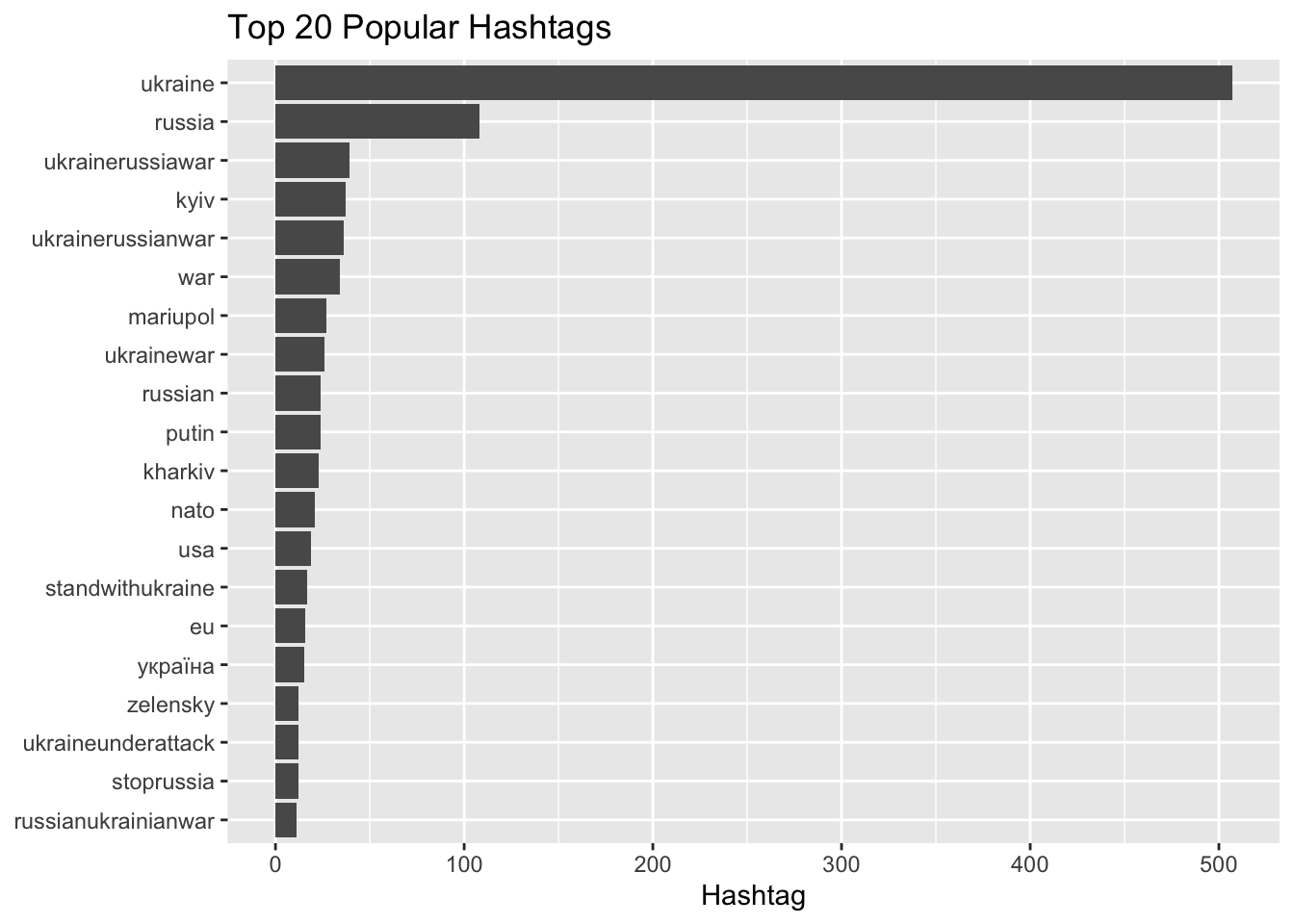 And if you want to see these top hashtags in a wordcloud, here it is:
And if you want to see these top hashtags in a wordcloud, here it is:
wordcloud.hashtags(tweets) Would you think that most people used iPhones or Twitter Web Application to post tweets? Or is it Android? Let’s explore that with a charming pie graph:
Would you think that most people used iPhones or Twitter Web Application to post tweets? Or is it Android? Let’s explore that with a charming pie graph:
tweet.sources(tweets)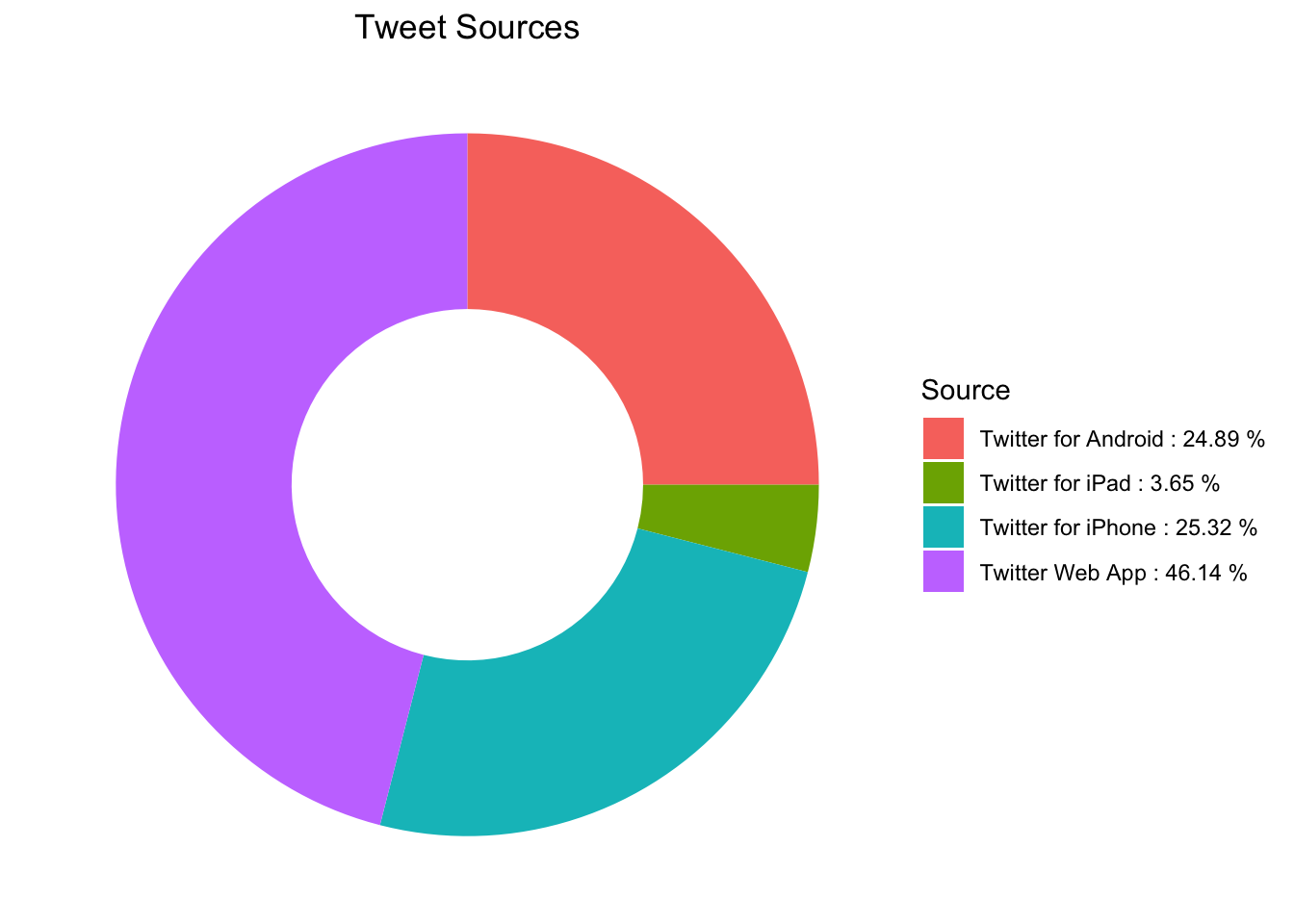 In what languages were tweets sent in?
In what languages were tweets sent in?
tweet.lang(tweets)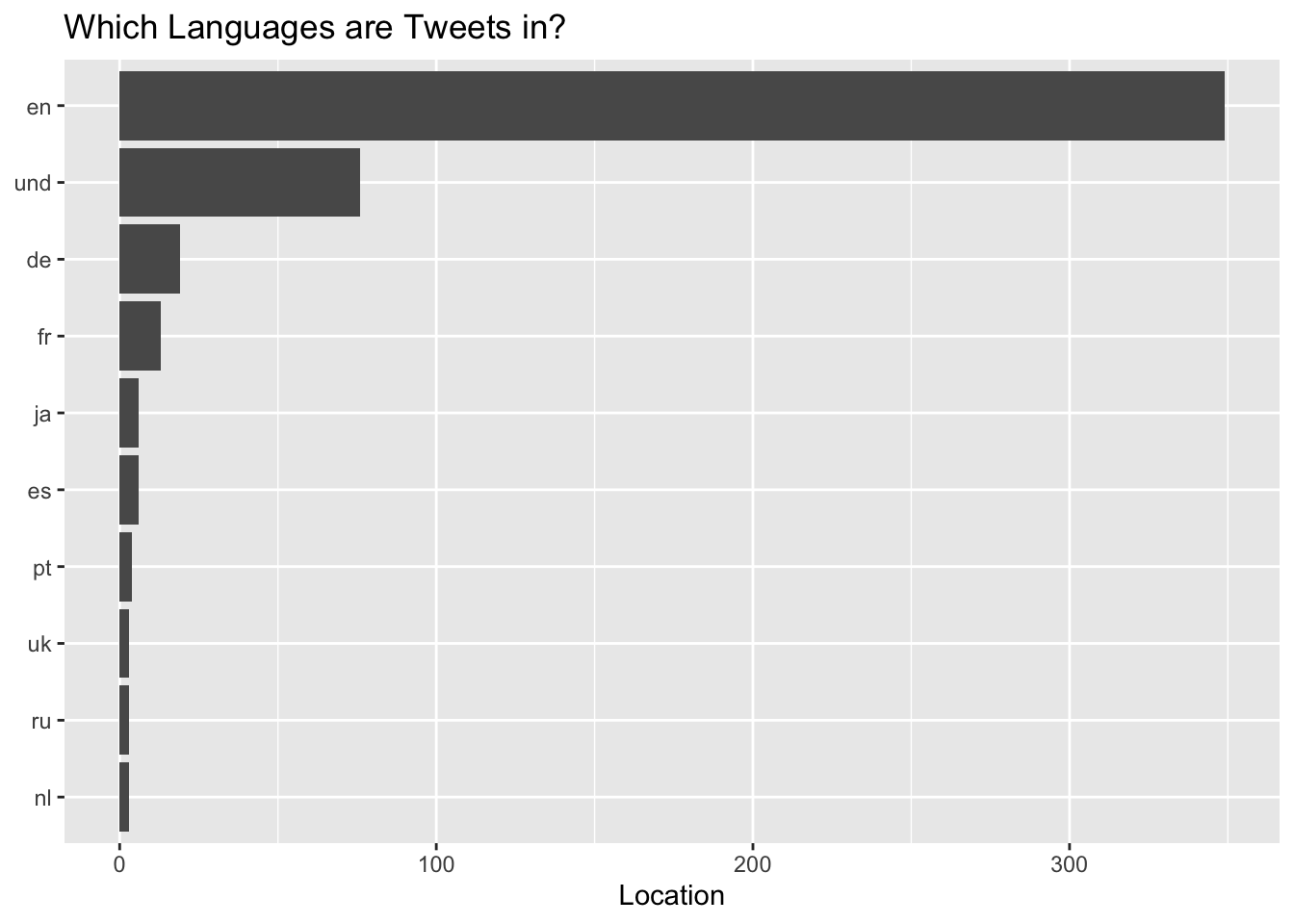 This is the word cloud for the most frequent words in tweets:
This is the word cloud for the most frequent words in tweets:
wordcloud.tweets(tweets) If you want to see some randomly selected tweets, use
If you want to see some randomly selected tweets, use view.randomly function. The number of tweets you can see here is set to 3 by default, but you can change it with the argument n.
Rtwitter::view.randomly(tweets, n=5)| user_name | text |
|---|---|
| Christopher Viele |
#UKRAINE https://t.co/FWAB6c58Zm |
| Andrea James 💙 | 1/ The Prosecutor of the International Criminal Court has established a portal through which any member of the public may submit evidence of possible war crimes or crimes against humanity that may have been committed in #Ukraine |
| Jean Brun 🇺🇦 | 🔴 #Guerre en #Ukraine L’entretien en face-à-face de Volodomir #Zelinsky a été réalisé a destination des 56 membres de l’Union européenne de radiodiffusion (#EBU). Il a été animé sur place par Eurovision News Events et le radiodiffuseur public ukrainien, UA:PBC. |
| PatBoy |
EXFILTRATION DES DEUX DERNIERS JOURNALISTES DE #AssociatedPress à #Marioupol Les héroïques #MstyslavChernov et #EvgeniyMaloletka Their report inside : #Ukraine #UkraineInvasion #UkraineUnderAttack #UkraineRussiaWar #PutinWarCriminal #Russia #Putin https://t.co/1z02PgX6Z9 |
| The Lore Report | The latest World News! https://t.co/rF0Ibl6E4u Thanks to @eldispensador @eaGreenEU @TrademarkCo #ukraine #news |
# n normally is set to 3 (default)That’s it, for now! There are definetely some things that need to be developed, and more functions to be added. But for now, I hope these help!